第一章 量化设计与分析基础
引言
处理器惊人的性能改进
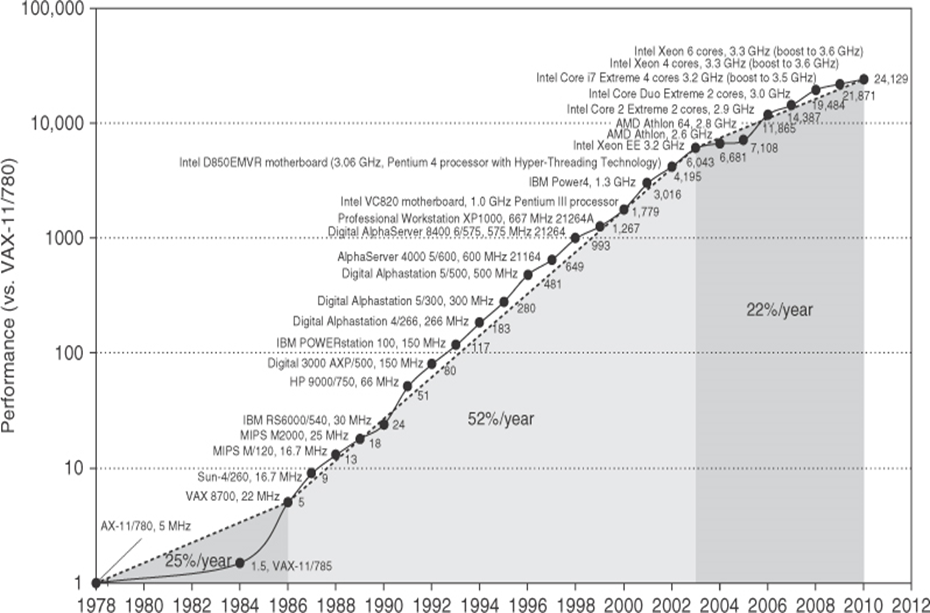
分析:
- 每年 25%(1978-1986): 性能增长主要依赖实现技术的进步
- 每年 52%(1986-2003): 性能增长依赖两方面:
- 系统结构革新(RISC,指令级并行 (ILP) 技术与Cache);
- 实现技术的进步
- 每年 22%(2004-2010): ILP 开发的限制,功耗限制,因此其后性能提升手段出现了以下趋势:
- ILP 变为 TLP and DLP(线程级并行和数据级并行)
- 更快的单核处理器 变为 单芯片多处理器(多核)
- 隐含在编译器和硬件的硬件级并行处理 变为 显示的程序级并行
计算机的分类
基于指令流和数据流数量分类 (XIXD)
基于市场分类
计算机系统结构定义与计算机的设计任务
计算机系统结构(原始定义)
计算机系统结构的原始慨念:
由程序员看见的计算机系统,就是慨念性结构和功能行为,以区分数据流动和控制逻辑设计的组成及物理实现。 – Amdahl, Blaaw, and Brooks, 1964
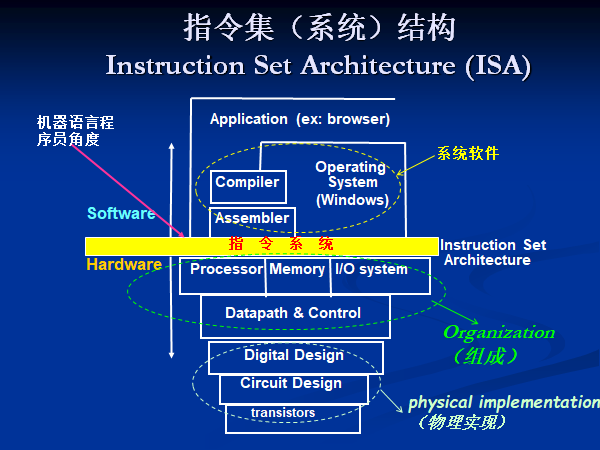
下面讨论计算机系统结构、计算机组成和物理实现及其关系关系。
经典的计算机系统结构是机器语言程序员所看到的传统机器级所具有的属性。它确定计算机系统的软、硬件界面。
计算机组成指的是计算机系统结构的逻辑实现,包括五大功能部件组成以及逻辑设计等。它着眼于机器级内各事件的排序方式与控制方式,各部件的功能以及各部件的联系。
计算机实现指的是计算机组成的物理实现,包括处理机、主存等部件的物理结构,器件的集成度和速度功耗,模块、插件、底板的划分与连接,信号传输,电源、冷却及整机装配技术等。它着眼于器件技术和微组装技术,其中器件技术在实现技术中占主导作用。
① 主存容量与编址方式(按位、按字节、按字访问等)的确定属于计算机系统结构。
② 为达到所定性能价格比,主存速度应多快,在逻辑结构上需采用什么措施(如多体交叉存储等)属于计算机组成。
③ 主存系统的物理实现,如存储器器件的选定、逻辑电路的设计、微组装技术的选定属于计算机实现。
具有相同计算机系统结构(指令系统相同)的计算机,因为速度要求不同等因素可以采用不同的计算机组成。例如,AMD Opteron 64与 Intel Pentium 4的指令系统相同,即两者的系统结构相同;但内部组成不同,流水线和Cache结构是完全不同的,相同的程序在两个机器上的的运行时间可能不同。
一种计算机组成可以采用多种不同的计算机实现。例如,主存器件可以采用SRAM芯片,也可以采用DRAM芯片。
系列机(family machine):是指由一个制造商生产的具有相同的系统结构,但具有不同组成和实现的一系列不同型号的计算机。
主要缺点:系列机为了保证软件的向后兼容,要求体系结构基本不改变,这无疑又妨碍了计算机体系结构的发展。
软件兼容性:同一个软件可以不加修改地运行于系统结构相同的各档机器上,而且运行结果一样,差别只是运行时间不同。
向后兼容:在某一时间生产的机器上运行的目标软件能够直接运行于更晚生产的机器上。
向上兼容:在低档机器上运行的目标软件能够直接运行于高档机器上。
计算机系统结构(现代定义)
计算机系统结构(现代定义):是在满足功能、性能和价格目标的条件下,设计、选择和互连硬件部件构成计算机。
系统结构覆盖了:
- 指令系统设计
- 组成(Organization):计算机设计方面的高层次
- CPU内部结构、存储器、I/O系统、多处理器、网络
- 硬件: 计算机的具体实现技术
- 详细逻辑设计、封装、冷却系统、板级设计,功耗等
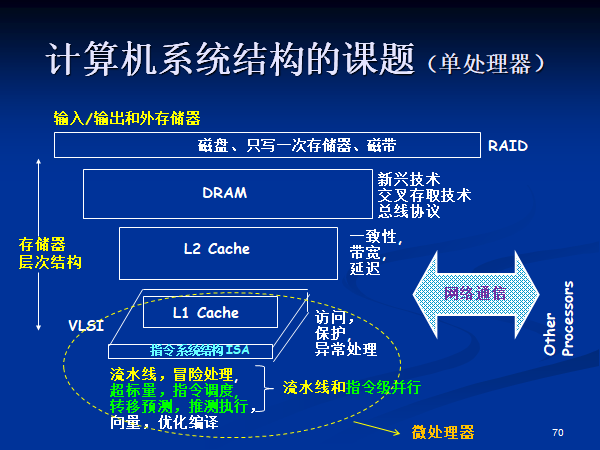
绿色部分 (ILP) 本课程不讲,只讲黄色部分。

第三章
结构冒险
数据冒险
解决办法:
- 软件方法:编译器插入NOP(暂停相关流水线)
- 硬件方法1:硬件插入 stall(暂停相关流水线)
- 硬件方法2:内部前推
- 硬件方法3:stall+内部前推(针对 store 指令)
硬件插入 stall
核心:ID 指令等前面的指令走完 WB (写寄存器)以后再继续(读寄存器)
停顿条件:(ID 级指令 rs1/2 == EXE/MEM 级指令 rd) && (EXE/MEM 级指令要写寄存器) && (ID 级要读寄存器)
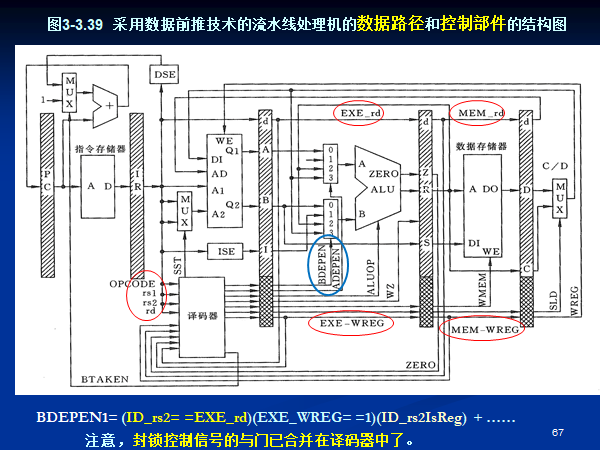
1 | DEPEN=(ID_rs1==EXE_rd)(EXE_WREG==1)(ID_rs1IsReg)+ |
ID_rs1IsReg条件是为了排除转移指令
1 | ID_rs1IsReg=and+andi+or+ori+add+addi+sub+subi+load+store |
进行简单改写:
1 | DEPEN = A_DEPEN + B_DEPEN |
内部前推 forwading
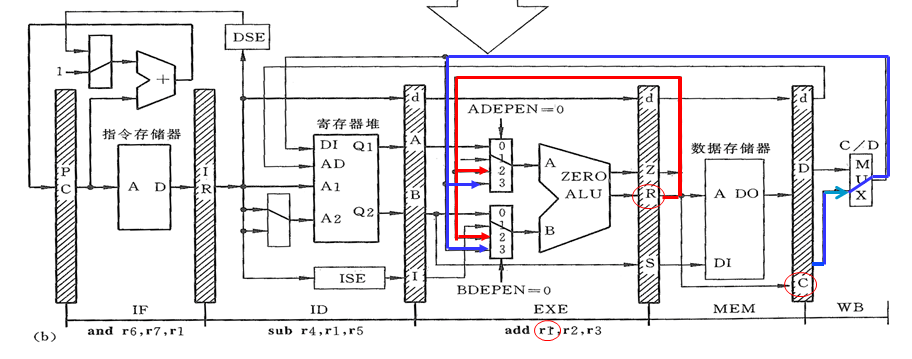
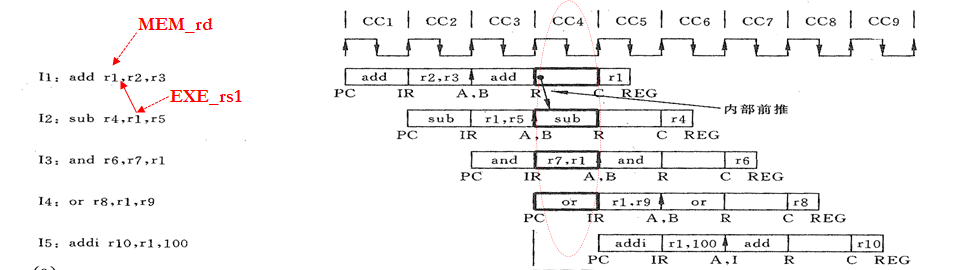
注意时序图里 forwarding 箭头的写法!
上一个计算结果可以直接从 ALU 里拿出来,至于多路选择哪个值,就是 ADEPEN 和 BDEPEN 的事情了。
| MEM_WREG | EXE_rs1=MEM_rd | WB_WREG | EXE_rs1=WB_rd | ADEPEN | ALU 输入选择(A端) |
|---|---|---|---|---|---|
| 1 | 1 | x | x | 2 | MEM_R |
| 1 | 0 | 1 | 1 | 3 | WB_C |
| 0 | x | 1 | 1 | 3 | WB_C |
| 其他情况 | 0 | A |
还是比较显然的。
B 端就比 A 端多一个条件:当 EXE_rs2IsReg 成立时就走立即数 (BDEPEN=2);其他情况下,按 A 端规则进行判断。
和 stall 不同的是:
- forwarding 考虑的是 EXE 指令和 MEM/WB 指令的关系,stall 考虑的是 ID 指令和 EXE/MEM 指令的关系
- forwading 不需要考虑转移指令,因为这类指令走不到 EXE 级
进行改进:将检测数据相关的时间从 EXE 级提前到 ID 级。
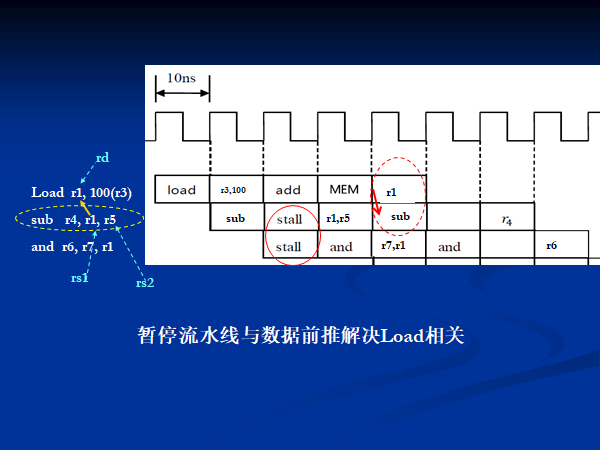
处理 load 指令: stall + forwarding
1 stall + 1 forwading 可以解决 EXE 级 store 和 ID 级 ALU 的数据冲突(称为 load 冒险)。
0 stall + 1 forwading 可以解决 MEM 级 store 和 ID 级 ALU 的数据冲突。
总结
| 指令 | stall/nop | forwarding |
|---|---|---|
| ALU 指令 | 2 stalls | 0 stalls + 1 forwarding |
| store 指令 | 2 stalls | 1 stall + 1 forwarding |
控制冒险
三种解决方法
- 暂停流水线(插 nop 或使用硬件方法)
- 假定转移不发生(针对条件转移)
暂停流水线
使用软件方法的话,beq bne需要前插 1 个 nop,后插一个 nop;branch 需要后插一个 nop。
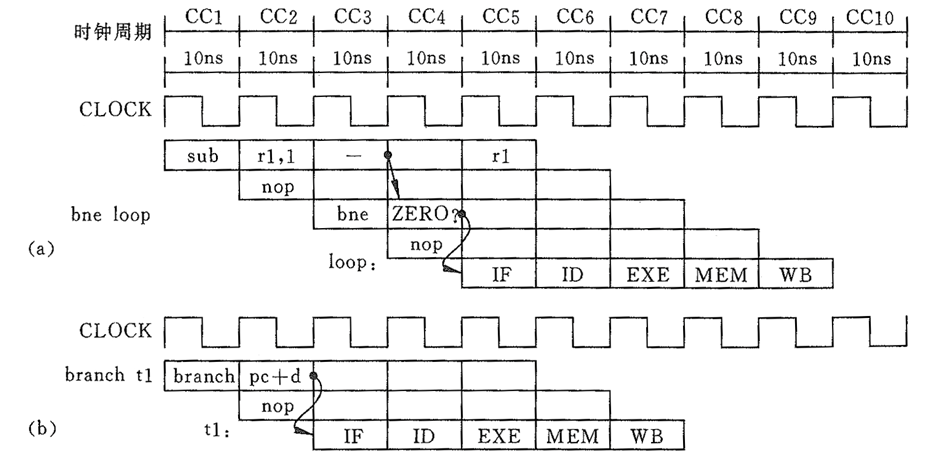
使用硬件方法就要麻烦一些了。
首先要终止后面一条指令的执行,不然转移发生的时候,后一条指令已经到 ID 了,还将继续执行。
解决办法和 stall 类似,封锁指令的 WZ、WMEM、WREG。
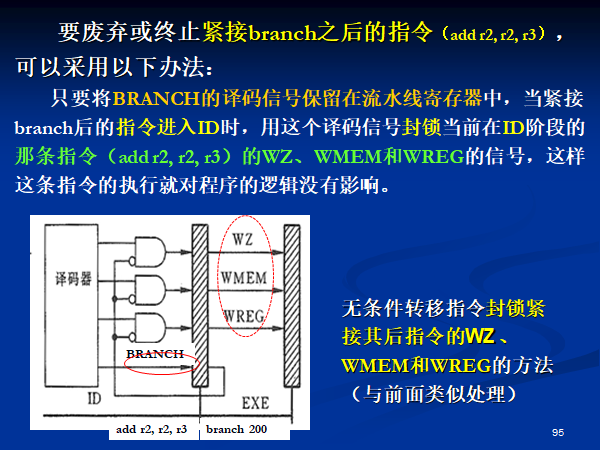
假定转移不发生
这个其实很简单,就是在装流水线的时候,假设转移不发生,该咋装咋装。
所以,如果真的没有转移,1 次停顿都不会有;如果真的转移了,此时在流水线的指令全部要停掉(这个时候,其实就是硬件方法暂停流水线)。
例题
假设某机器的流水线,转移目标地址计算需要2个流水段,转移条件形成需要3个流水段,完成一个流水段的操作用一个时钟周期。假定解决控制冒险有三种方法:停顿流水线、转移预测未选中、转移选中。试计算条件转移指令采用这三种方法在转移发生与转移不发生所产生的停顿时钟周期数
| 停顿周期数 | 条件转移发生 | 条件转移未发生 |
|---|---|---|
| 停顿流水线 | 2 | 2 |
| 预测转移未选中 | 2 | 0 |
| 预测转移选中 | 1 | 2 |
延迟转移
注意到 branch/beq/neq 后的代码一定会被执行。前面的解决办法是在这个位置放一个 nop 或 stall 解决问题禁止它产生效果。但是能不能利用这个特性,让它在这个时候执行一点代码呢?
这个就和没有流水线的 MIPS 有点不一样了:
1 | Lop: load r1, 20(r2) |
上面没有优化的代码需要 3 个 nop。(假设除了 subicc 以外,其他指令不修改标志位,所以 subicc 不需要放在 bne 前)优化以后,一个 nop 都不需要!
1 | Lop: load r1, 20(r2) |
非常神奇的是,store 指令摆在 bne 以后,但每次跳转仍然会被执行。这是和单周期 CPU 非常不同的一点。
