这里只用到了 Hadoop 的 Hadoop Distributed File System (HDFS),即分布式文件系统。而数据处理是交给 Spark 了。
安装
注意 Hadoop 的 namenode 默认管理 Web 页面是 http://localhost:9870/,而从 hdfs 协议访问 namenode 是从 9000 端口。
Hadoop 分布式文件管理
管理 HDFS 的命令和 Linux 的命令很像。
1 | cd $HADOOP_HOME |
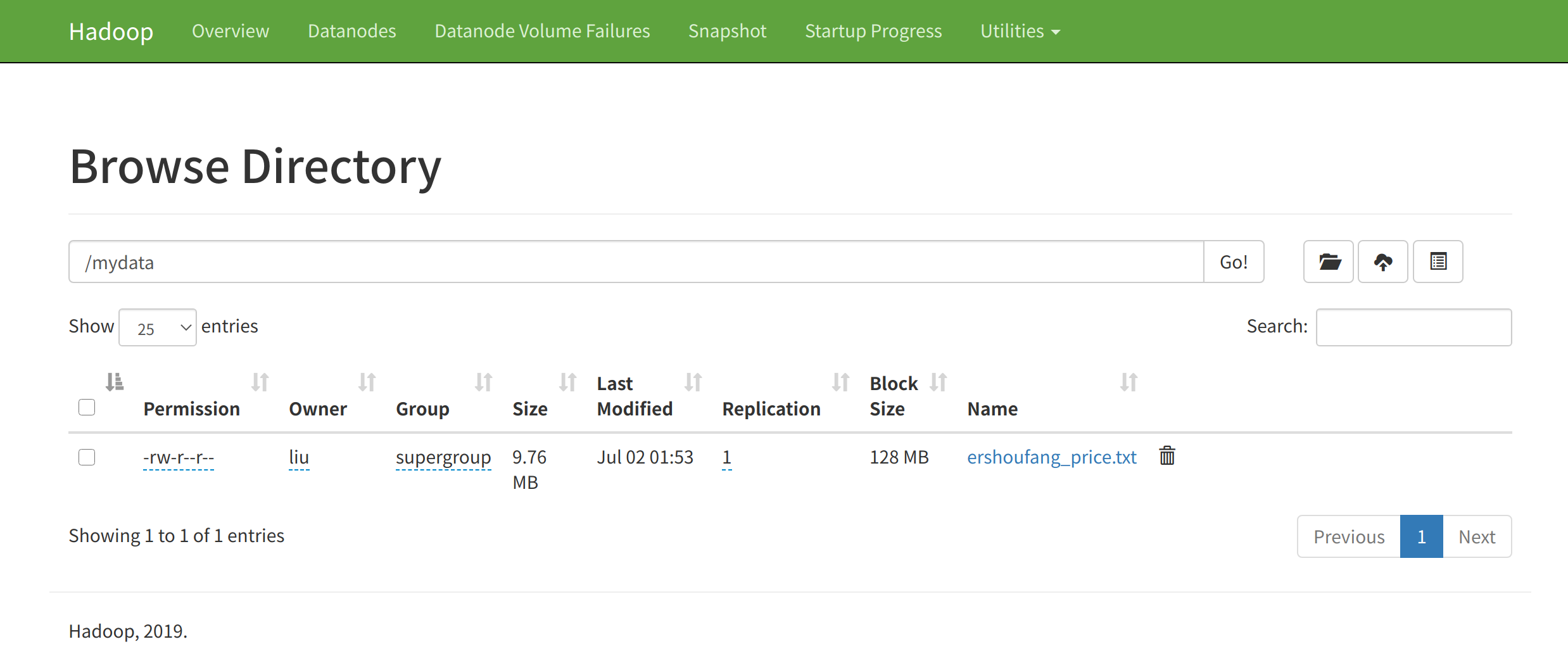
为配合后面的测试,将爬虫爬取的二手价格数据下载后,上传到 HDFS:
1 | cd $HADOOP_HOME |
Spark
还需要安装 pyspark。
1 | pip3 install pyspark |
然后将环境变量写入 /etc/profile:
1 | export PYSPARK_PYTHON=python3 |
需要注销才能生效。
顺便一提,安装过程中还会自动安装 py4j,因为 Spark 是运行于 Java 之上,需要用 Python 读取 JVM 中的对象。
读取文本文件
尝试读取上面上传的 ershoufang_price.txt。这里的 localhost:9000 可以在 Web 端看到。然后编写一下的 Python 代码,尝试从 HDFS 读取文本文件的内容。
1 | from pyspark.sql import SparkSession |
如果输出了 44', '杭州,下沙,77,17382,44', '杭州,下沙,77,17382,44', '杭州,下沙,77,17382,44', '杭州,下沙,77,17382,44', '杭州,下沙,92,20924,43'] 等,则正常。
如果报错:Python in worker has different version 2.7 than that in driver 3.7, PySpark cannot run with different minor versions.Please check environment variables PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON are correctly set.,则检查一下是否把环境变量加入 /etc/profile。
统计城市房源数并存入临时数据库
接下来尝试将数据存到数据库。为测试语法,这里直接输出到 Spark SQL 的全局临时表中,然后做一个简单的查询。
这里的代码是紧接着上面的 textFile = sc.textFile(filePath)。
1 | from pyspark.sql import SparkSession, Row |
输出结果如下:
1 | +----+-----+ |
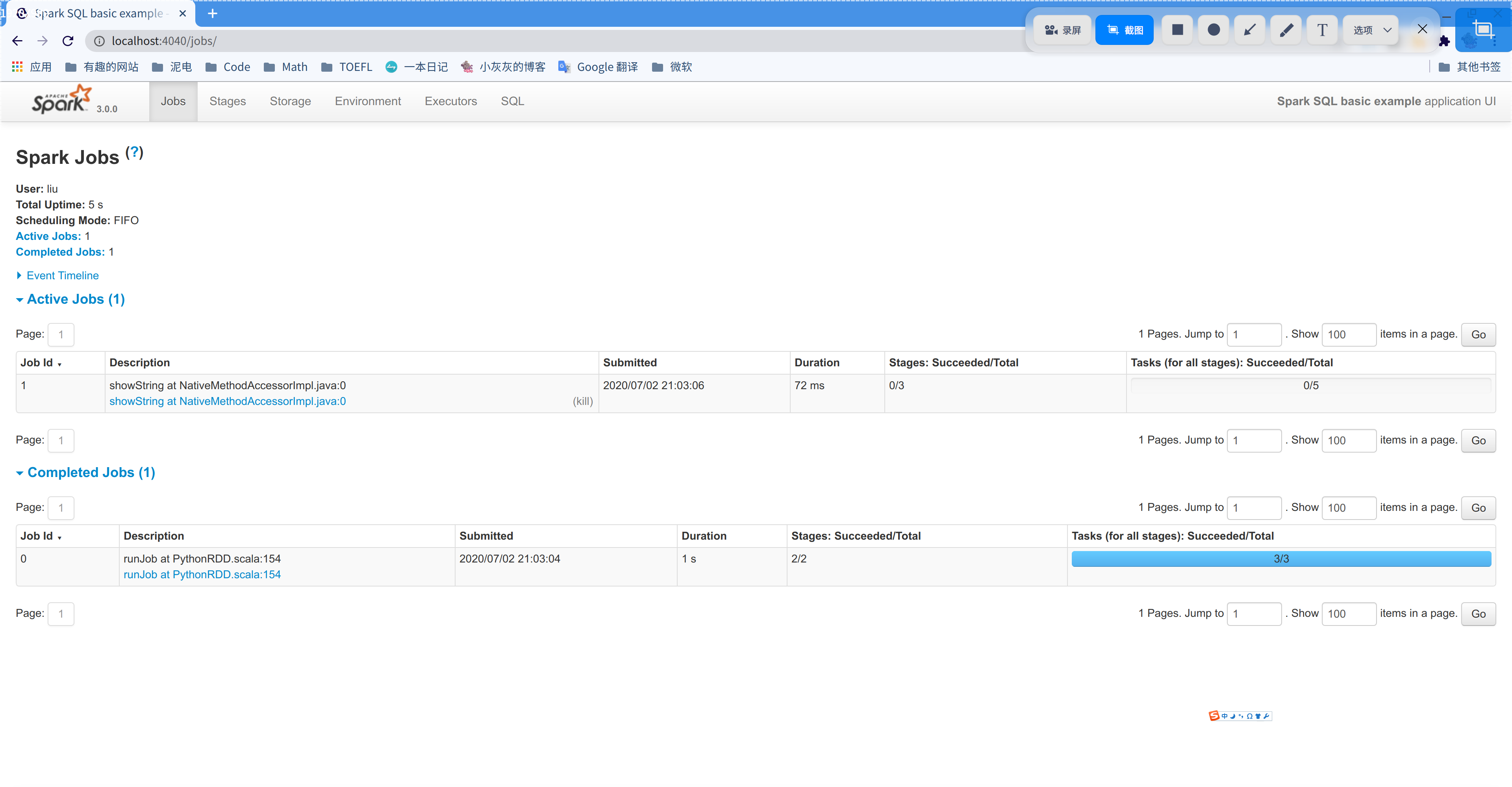
重新运行代码,并在 dataFrame.createGlobalTempView('city') 一行打断点暂停。暂停以后可进入 localhost:4040,即 Spark 的管理页面。
将数据存入 MySQL 数据库
这里首先需要提前配好 MySQL 数据库。
然后为 Spark 下载额外的 jar 包,用以操作 MySQL 数据库。
1 | wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.20/mysql-connector-java-8.0.20.jar # 根据数据库版本而定 |
接着上文的 dataFrame = spark.createDataFrame(rowRdd) 写:
1 | dataFrame = spark.createDataFrame(rowRdd) |
